Archive
Statistik Kecelakaan Tambang di Indonesia
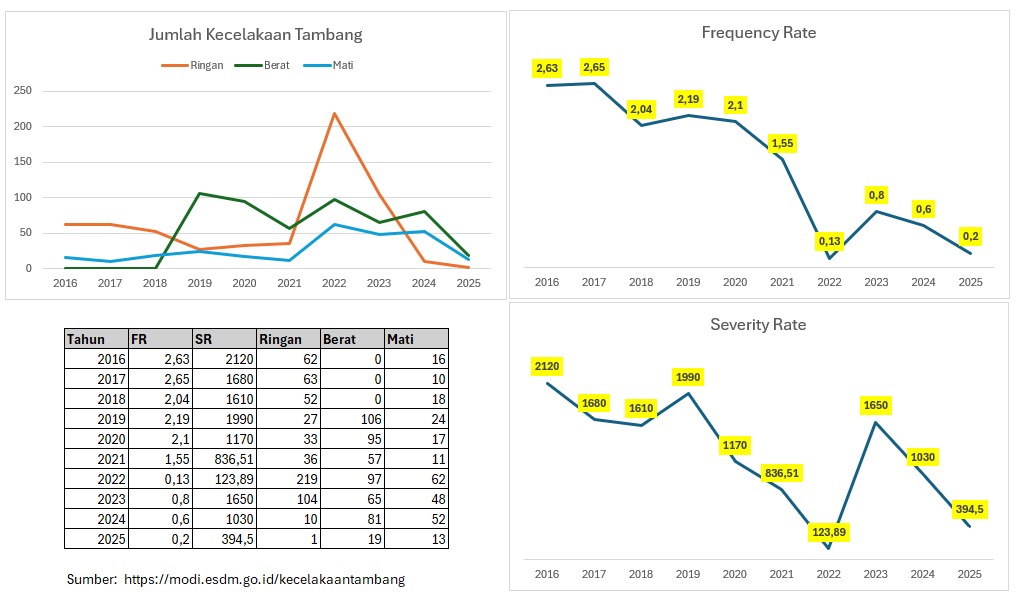
Berikut adalah Statistik Kecelakaan Tambang di Indonesia berdasarkan data Minerba per 22 Juni 2025 (klik disini). Di dalamnya dapat kita temukan jumlah kecelakaan tambang (ringan, berat, mati), Frequency Rate (FR), dan Severity Rate (SR). Panduan penilaian untuk FR dan SR dapat kita temuan di Kepdirjen 10.K/2023 sebagai berikut,
Frequency Rate (FR)
- Dasar: FR >= 0,20
- Reaktif: 0.10 <= FR < 0.20
- Terencana: 0.06 <= FR < 0.10
- Proaktif: 0.02 <= FR < 0.06
- Resilient: FR < 0.02
Severity Rate (SR)
- Dasar: SR >= 100
- Reaktif: 40 <= SR < 100
- Terencana: 20 <= SR < 40
- Proaktif: 10 <= SR < 20
- Resilient: SR <10
Analisis Skala Likert
Banyak pertanyaan ke saya terkait dengan analisis skala likert, skala likert sering digunakan dalam kuesioner/survei persepsi dengan gradasi data ordinal 1 s.d. 5 (Sangat Tidak Puas, Tidak Puas, Netral, Puas, Sangat Puas) dan variasinya. Setiap aitem pertanyaan dicari distribusi frekuensinya dan dibuatkan grafik batang atau tabel frekuensi yang menunjukkan distribusi terbesar sampai terkecil (Statistik Deskriptif/Univariate). Akan tetapi bagaimana analisis korelasinya dengan variabel demografi (Statistik Inferensi/Bivariate) ?
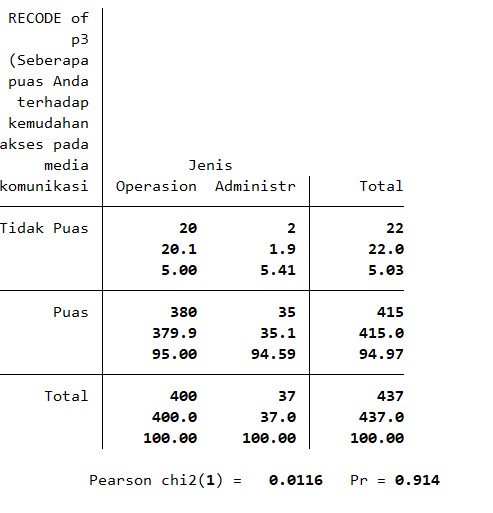
Sebagai contoh pada tampilan diatas, aitem pertanyaannya adalah Seberapa puas Anda terhadap kemudahan akses pada media komunikasi ? Skala Likertnya adalah 1 s.d. 4 (Sangat Tidak Puas, Tidak puas, Puas, Sangat Puas) dengan total 437 responden pada divisi operasional dan Administrasi. Hal pertama yang perlu kita lakukan adalah menjadikannya dicotomous, yaitu menjadikan Skala Likertnya menjadi dua value saja yaitu Tidak puas (Sangat Tidak Puas + Tidak Puas) dan Puas (Puas + Sangat Puas).
Hal kedua yang perlu kita lakukan selanjutnya adalah membuat tabel silang seperti tampilan diatas untuk mencari distribusi frekuensinya. Terlihat bahwa responden yang puas di divisi operasional adalah 95.00 % dan administrasi adalah 94.59% (perbedaan 0,41%). Pertanyaan berikutnya adalah Apakah perbedaan 0.41% ini signifikan ?
Hal tersebut bisa kita jawab dengan melihat nilai p pada chi square yang diberikan oleh program statistik, terlihat nilai p valuenya = 0.914 ( > 0.05 ). Nilai p value > 0.05 menunjukkan bahwa perbedaan itu tidak signifikan! sehingga dapat disimpulkan secara statistik bahwa tidak ada perbedaan signifikan kepuasan responden divisi operasional dan administrasi dalam persepsi kemudahan akses media komunikasi.
Semoga bermanfaat
Cross Tabulations – What is it?
Dalam analisis data kuantitatif, kita mengenal perangkat Cross Tabulations untuk melihat korelasi antar variabel. Cross Tabulation adalah tabel yang disajikan dalam bentuk baris (variabel dependent/predictor/cause) dan kolom (variable independent/outcomes) – seperti pivot table dalam Excel – serta digunakan untuk data nominal dan/atau ordinal.
| Apakah Anda melakukan safety talk setiap hari? | Pengawas | Operator | Total |
| Tidak | 187 22,42% | 501 29,70% | 688 27,29% |
| Ya | 647 77,58% | 1186 70,30% | 1833 72,71% |
| Total | 834 100% | 1687 100% | 2521 100% |
Dari tabel di atas, dapat dilihat bahwa jumlah operator yang melakukan safety talk harian ada 1186 (dari 1687 orang) dan jumlah pengawas ada 657 (dari 834 orang), sehingga orang dengan mudah menyimpulkan bahwa Operator lebih banyak melakukan safety talk harian daripada pengawas!
Akan tetapi,
Kalau kita buat dalam bentuk persentase (%), kita mendapatkan data bahwa jumlah operator yang melakukan safety talk harian sebesar 70,30% sedangkan pengawas sebesar 77,58%, artinya pengawas lebih banyak melakukan safety talk harian daripada operator dengan perbedaan sebesar 7,28%!
Pertanyaan berikutnya adalah apakah perbedaan 7,28% ini signifikan ? Untuk menjawab hal tersebut, maka diperlukan uji statistik untuk data nominal/ordinal yang disebut chi-square. Dengan menggunakan kalkulator statistik didapatkan nilai chi-square dari tabel diatas adalah 14,883 dengan nilai p = 0,000 (< 0.05), karena nilai p < 0.05 maka dapat disimpulkan bahwa perbedaan itu adalah signifikan!
Nilai chi-square menunjukkan apakah ada perbedaan signifikan antar variabel tetapi tidak dapat menunjukkan seberapa kuat korelasi / hubungan antar variable tersebut. Untuk melihat seberapa kuat korelasi / hubungan antar variable tersebut kita menggunakan gamma and kendall’s Tau-b. Dengan menggunakan kalkulator statistik didapatkan nilai gamma = 0,1875 dan nilai kendall’s tau-b = 0,07, ini menunjukan korelasi yang lemah (mendekati nilai 1 adalah korelasi yang kuat).
Dari penjelasan di atas, dapat disimpulkan bahwa cross tabulations merupakan salah satu cara untuk menampilkan korelasi antar variabel yang digabungkan dengan uji statistik yang tepat untuk membuat interpretasi / kesimpulan sahih.
Semoga bermanfaat (ditulis dari Tembagapura – FN)
Is Average Number a Lie?
Judul ini sengaja saya pilih karena banyak hal dalam pengukuran kinerja K3 yang kita ukur dan tampilkan dengan nilai rata-rata. Dalam ilmu statistik kita mengenal ada ukuran pemusatan dan ukuran penyebaran untuk menggambarkan karakteristik sekelompok data. Nilai rata-rata, median, dan modus masuk dalam ukuran pemusatan sedangkan range, simpangan baku, koefisien variasi masuk dalam ukuran penyebaran.
Sebagai contoh, saya akan memberikan dua area kerja dengan kelompok data jumlah temuan inspeksi K3 setiap bulan sebagai berikut:
| Area Kerja A | 30,31,28,30,29,29,32,30,32,29 | rata-rata= 30 median=30 modus=30 simpangan baku=1.2 koefisien variasi=4% |
| Area Kerja B | 33,29,30,31,34,28,29,29,27,30 | rata-rata=30 median=29 modus=29 simpangan baku=2.0 koefisien variasi=7% |
Dua area kerja di atas memiliki nilai rata-rata yang sama yaitu 30, apakah kita bisa menyimpulkan bahwa kedua area memiliki jumlah temuan inspeksi K3 yang sama dan tidak berbeda secara signifikan ?
Secara awam, kita bisa mengatakan YA! karena kedua area memiliki nilai rata-rata yang sama yaitu 30 sehingga prioritas tindakan koreksi akan sama untuk keduanya.
Secara statistik, kita bisa mengatakan TIDAK! karena area kerja B memiliki kelompok data yang lebih bervariasi daripada area kerja A. Hal ini dapat dilihat dari Koefisien variasi sebesar 7% (selisih 3% dari area kerja A), sehingga prioritas tindakan koreksi akan lebih difokuskan kepada area kerja B
Dari penjelasan di atas, dapat kita simpulkan bahwa kita harus lebih berhati-hati ketika hendak menggambarkan sekelompok data dengan ukuran pemusatan saja (istilah lain distribusi normal) karena pada kenyataannya ada kelompok data yang tidak berdistribusi normal karena variasinya yang tinggi sehingga ukuran penyebaran menjadi penting!
Semoga bermanfaat (ditulis dari Tembagapura – FN)
